
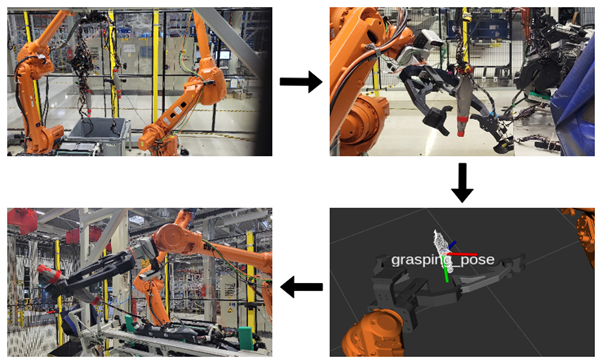
First, one of the manipulators retrieves the wiring harness out of the box. As the manipulator reaches the planned pose, a second manipulator equipped with a vision system collects data and estimates the grasping pose necessary to hold the selected component securely.
The vision system consists of a deep neural network pipeline for instance segmentation based on RGB camera input. Furthermore, sensor data fusion enables the creation of a 3D component reconstruction, and its shape is used to determine the final grasping position. Subsequently, with the wiring harness component securely held, the manipulators perform a drag-and-drop task. These steps are repeated for all key components until they are correctly placed in their designated locations.
Our team is actively working on performance improvements, focusing on meeting the industrial time constraints. In parallel, efforts are being made to enhance the robustness of the vision system, ensuring its capability to handle a wider range of edge cases.
Written by PUT